Feeds Importers + Config
RC’s Drupal site uses three separate contributed modules to facilitate the importation of fields into the Drupal database:
- Feeds — the base feeds module, which enables the importation of content fields onto any Drupal content type.
- Feeds Extensible Parsers — extends the feeds module to enable the importation of XML documents and, vitally, parse them via XPath.
- Feeds Tamper — extends the feeds module to enable the transformation of content as part of the import process (e.g., a tamper could perform a search-and-replace on all imported content, removing certain words or tags).
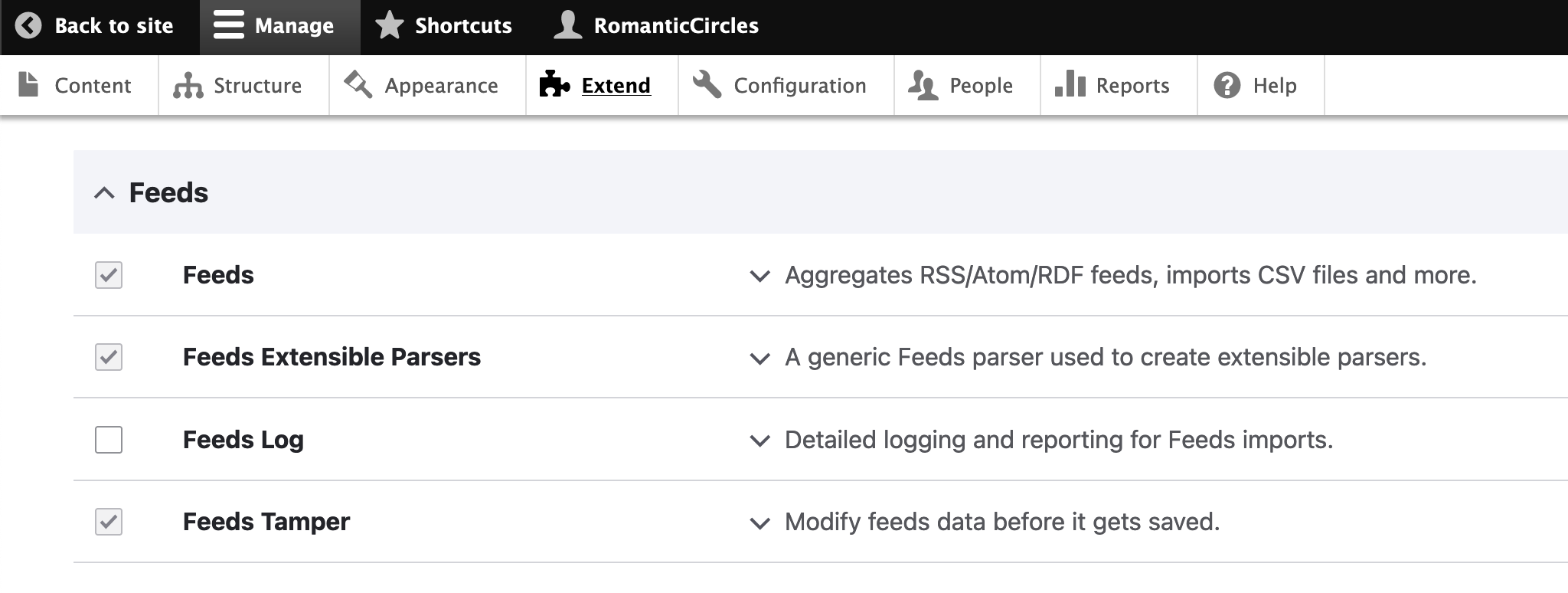
These three modules work seamlessly together in Drupal’s backend to enable you to create/configure and then run an importer. This technical guide covers the configuration of new or existing importers. If you simply need instructions on importing content using an existing importer, see Importing Content into the Drupal CMS in the Production Documentation.
Creating, configuring, and/or editing importers
Importers can be created and configured from the “Feed types” page under the admin menu’s “Structure” tab. From this page, you can create a new feed with “Add feed type” or edit an existing feed.
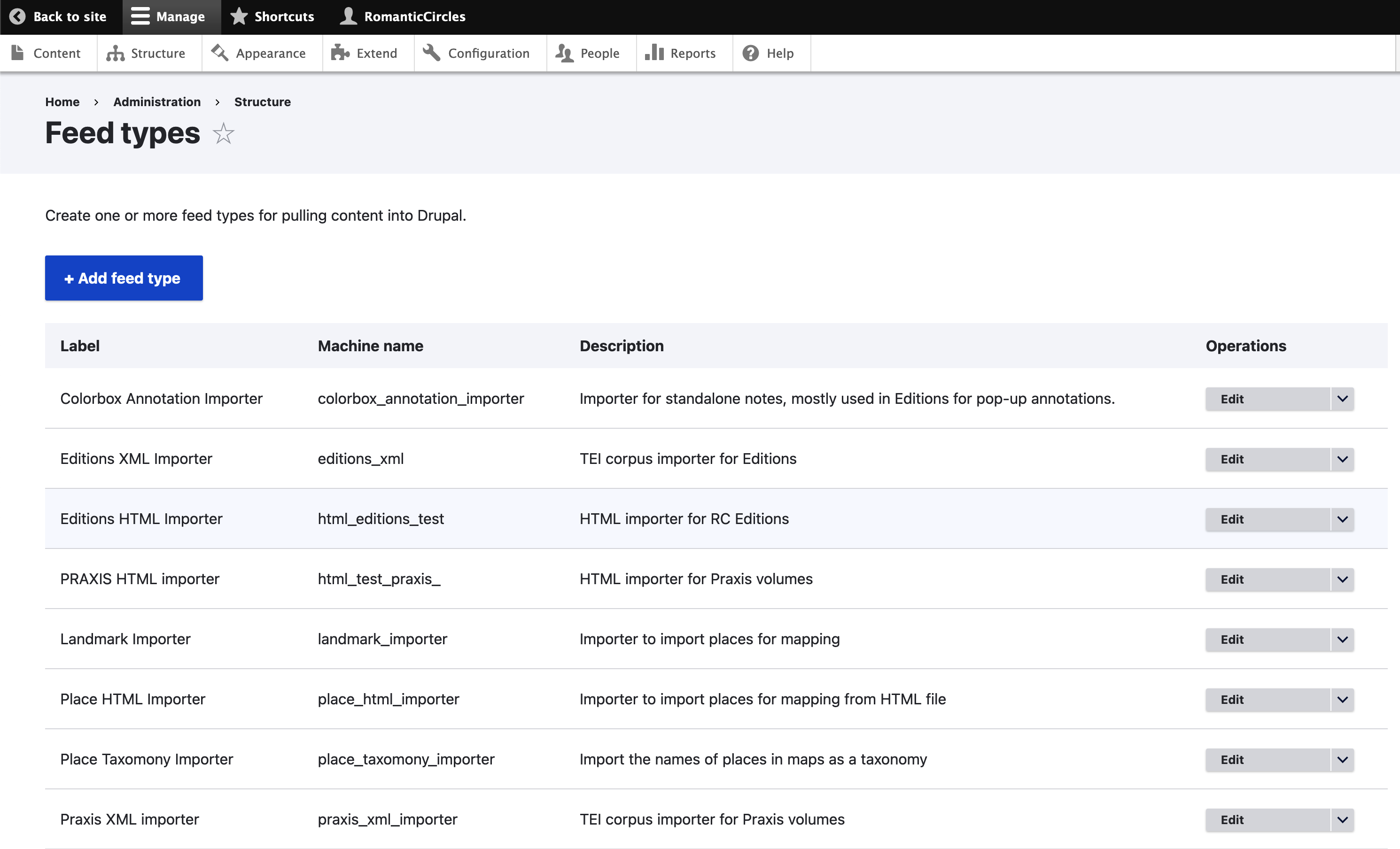
To configure an existing feed, simply click “edit” to go to its config page. On each feed’s config page, you’ll see several tabs:
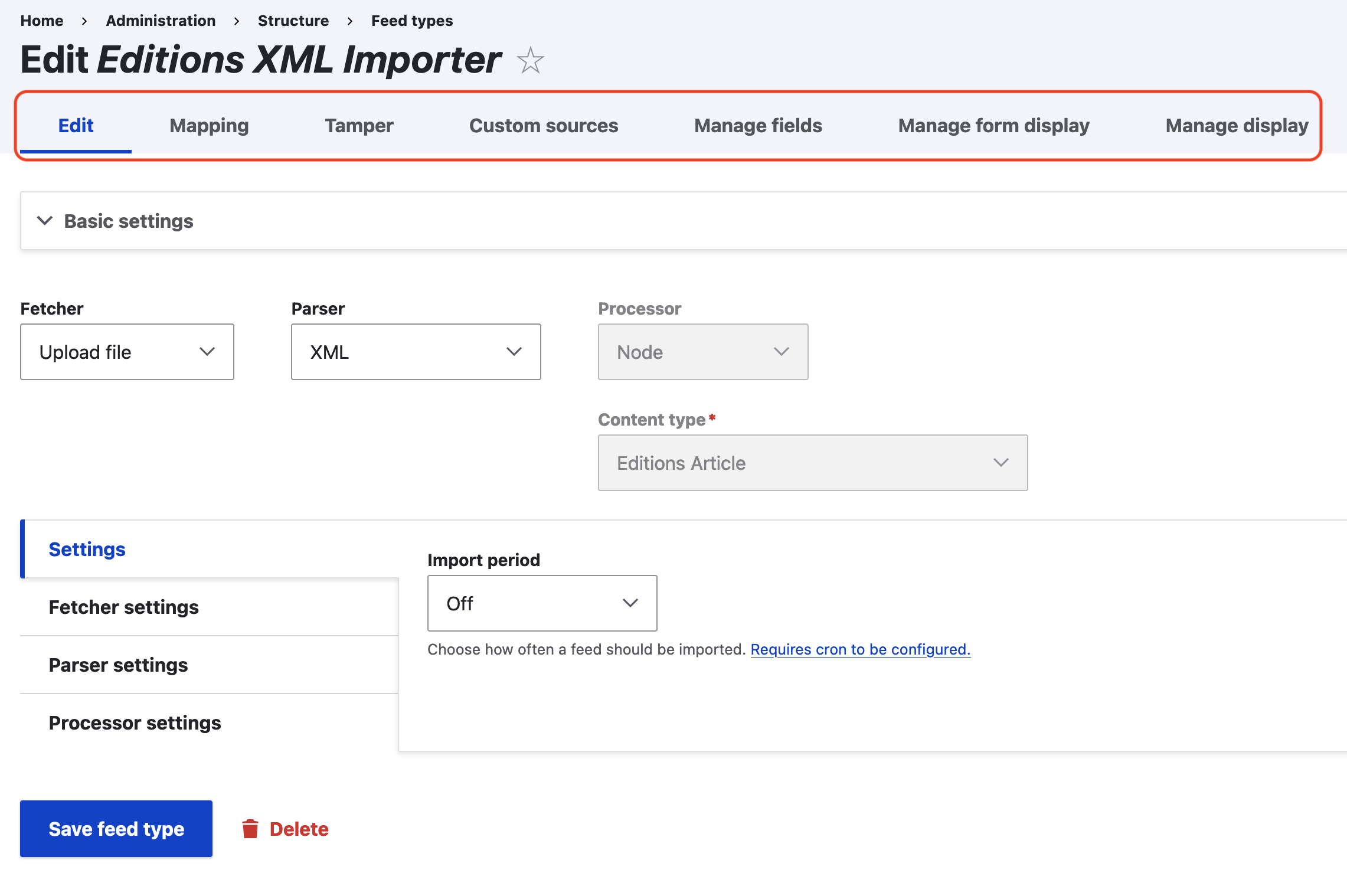
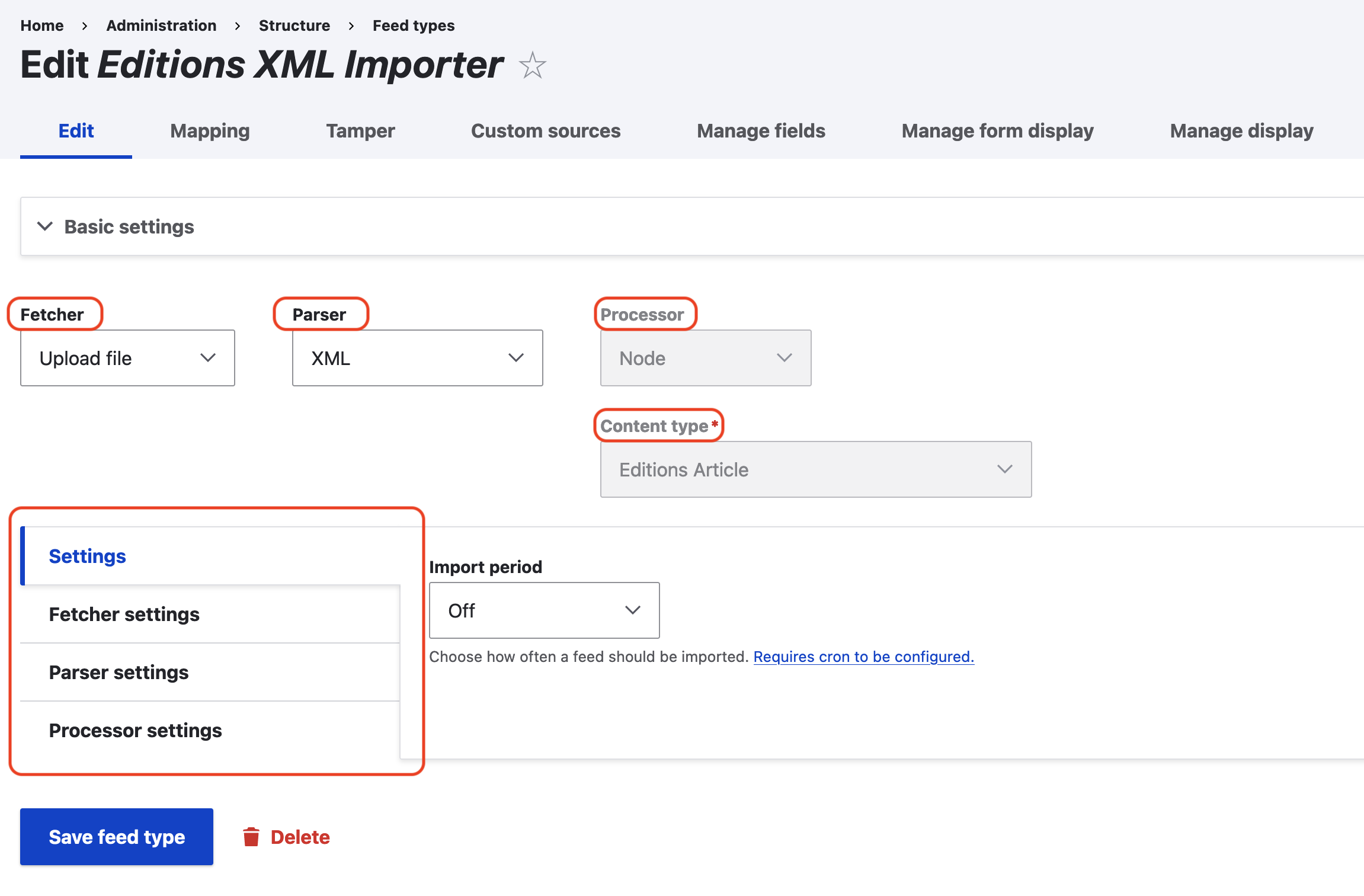
- Edit — controls the basic feed configuration. The fetcher tells Drupal how the database should fetch your imported file or content (usually an uploaded file or FTP directory). The parser selects what method the importer will use to parse imported content. We want to use XPath, so for normal imports this should be “XML.” The processor tells Drupal how to process the content parsed by the importer; this will usually be “node,” meaning Drupal should create a new node for each essay. The content type tells the importer what Drupal content type to create nodes/fields for. Each importer can only import into one content type; note that each content type has different possible/associated fields, which affects how content can be imported
- Settings: For RC importers, “Import period” will be set to off (no automatic imports). Under “Fetcher Settings,” ensure you set the importer to accept the type of file you’re importing and, if appropriate, point it to the right upload directory. Under “Processor settings,” almost certainly you’ll want to “Insert new content items” and to “Update existing content items.”
- Mapping — controls the behavior of the parser via Xpath. Set a “Context” for the base query, then select a “Target” field (the choice of fields is determined by the set content type). For each target field, you can configure a “Source” from the imported file(s). For new sources, you’ll need to “Configure new XML XPath source”; this is how the parser knows how to find a piece of content by an XML/HTML tag within the imported document. Under configuration, you can tell the parser to treat a field’s value as unique (the title will always be unique); set how to reference, or “tie together,” fields (usually by Title); and set whether entities should be autocreated (which could be useful if importing taxonomy terms, for instance). To configure XPath sources, you’ll likely need the RC Language Guide.
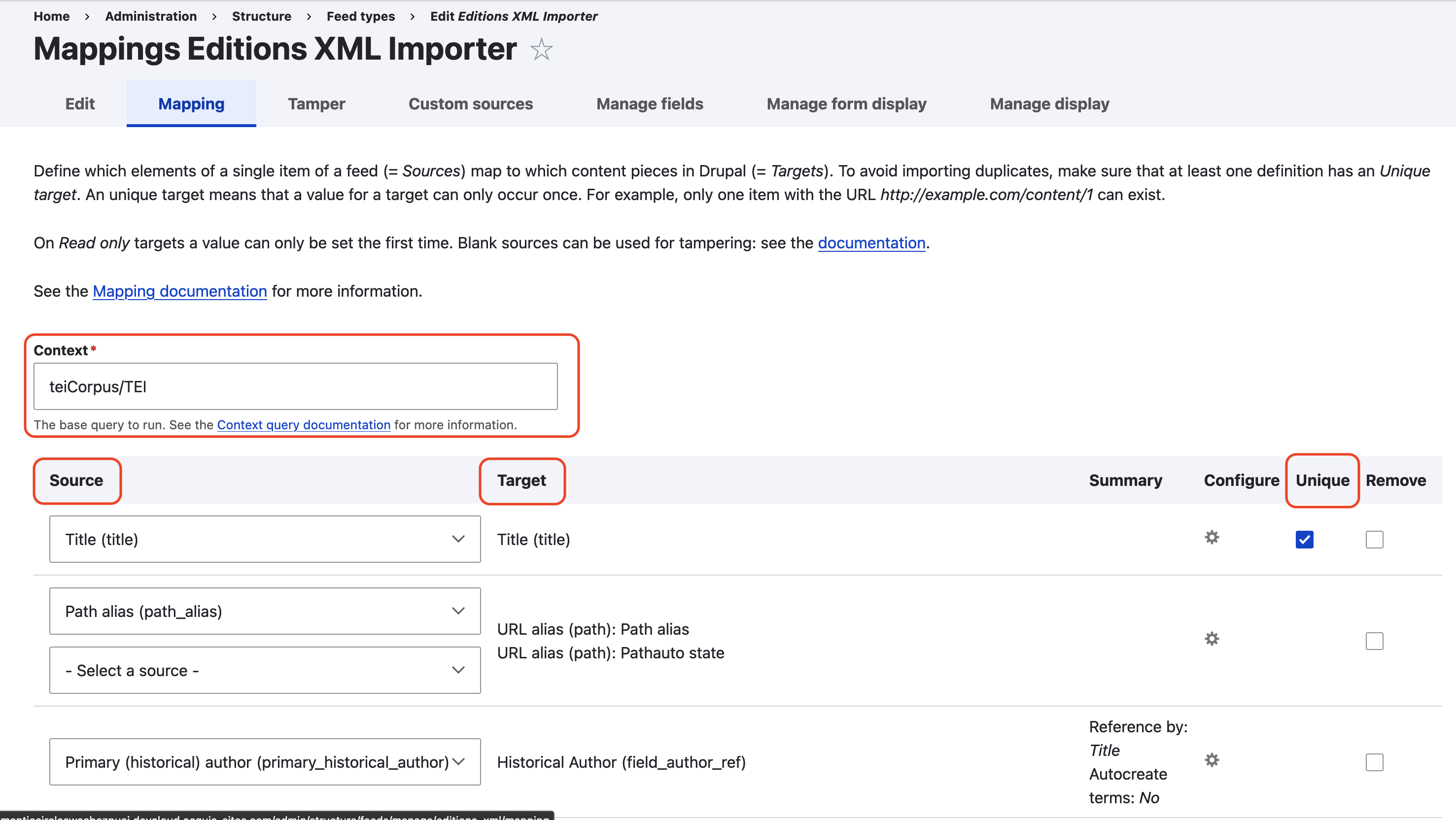
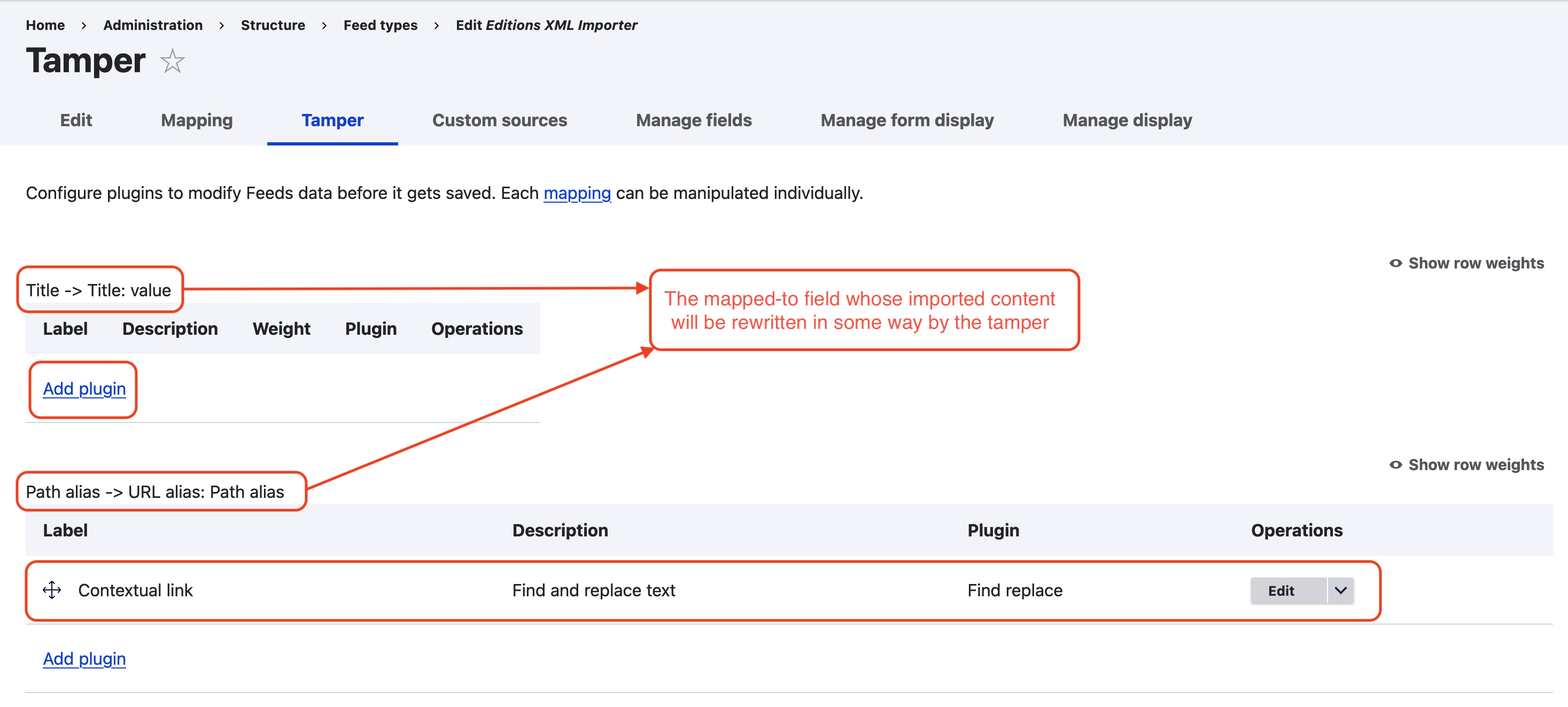
- Tamper — for each mapping target, you can set a “tamper” from this page that will alter or change the behavior of the imported content. Simply select “Add plugin” under the appropriate mapping target. An example of a simple tamper used on most importers is a filter to enforce contextual links, stripping the base domain from all imported RC links; to set it up, simply add the “Find replace” plugin, set it to find
https://romantic-circles.org/, and leave the replacement field blank (which will simply delete the “found” text). You can also use this functionality to, for instance, force the importer to import content with a specific node as parent content (as is necessary, for example, when importing mapping data).
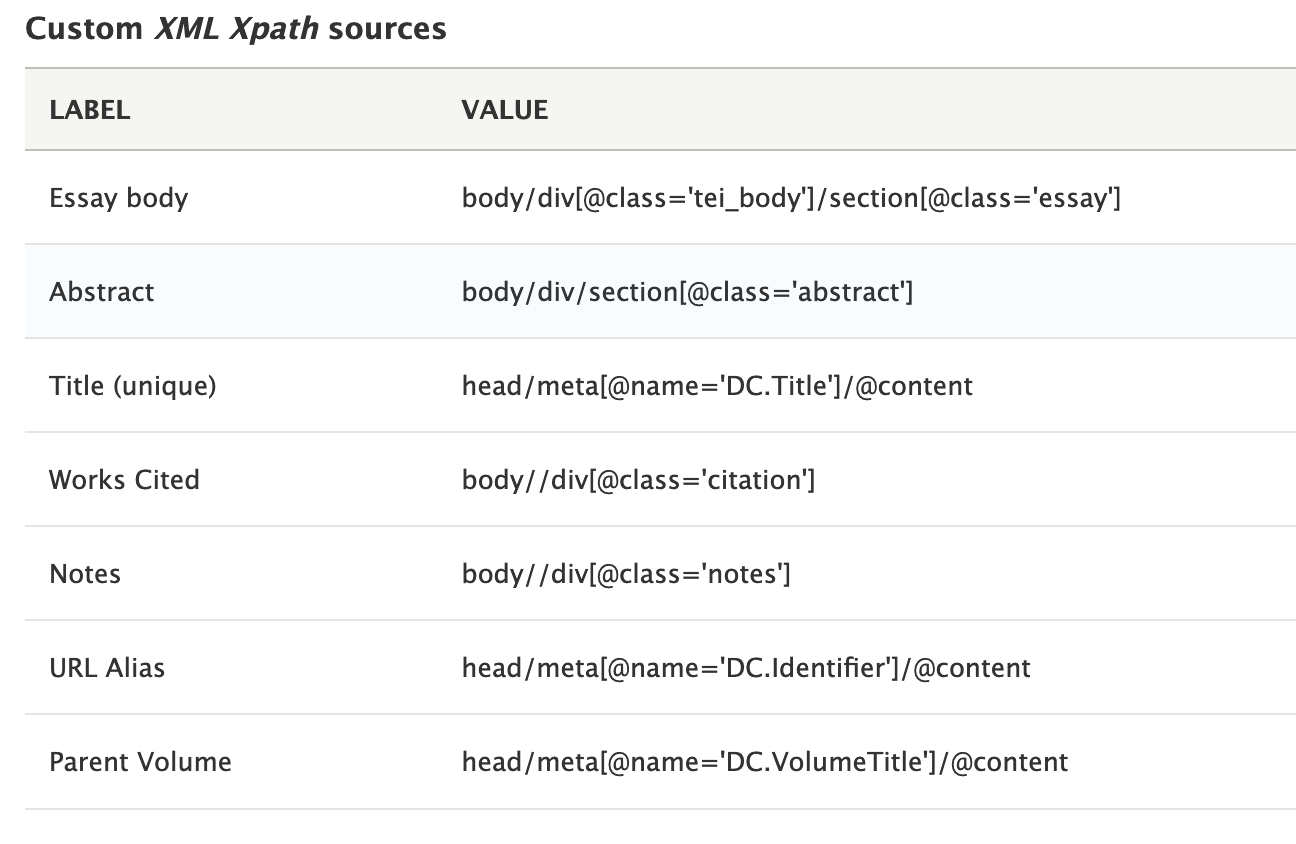
- Custom sources — this is an extremely useful tab that displays all your XPath configurations in a single place and allows you to edit them. Each target label is listed alongside its XPath mapping.
- Manage fields — can be used to add a new field to the import. Do not use.
- Manage form display — simply configures how information about the importer itself is captured in the database and displayed. No need to use.
- Manage display — controls the UI of the importer, which would be useful for periodic imports and the like. No need to use.
The process of setting up an importer seems rather intimidating, but through a bit of trial and error you’ll soon get how it works. To get the hang of using XPath mappings, it’s always best to create a new importer as a sandbox rather than editing an existing feed type (and potentially losing XPath mappings).
For more on using XPath, see the RC Language Guide.
Getting the mappings “right”
The best way to familiarize yourself with the process of setting mappings is to review the importers that already exist on the site. They reflect various shortcuts and use of selectors that will put you on the right path, so to speak.
Since XPath is so adaptable, there are probably dozens of ways to get to a “correct” mapping to import the field content you’re after. The importers don’t care how efficient your XPath is, only that it gets to a fetchable result. With this said, it can be helpful to keep in mind a few principles as you’re setting importer mappings:
- The “Context” field on the “Mapping” tab is your base query, meaning that any other mapping you set builds onto this path. The more broad your import needs to be, the more general the base query in the context field will be.
- If, for example, you’re simply grabbing content from a sequence of (parallel) XML nodes that are all located (in the TEI document) at
/TEI/text/body/div/listPlace/place/placeNamewith the XML tag logic<placeName id="BostonCommon">Boston Common</placeName>, you could set the context as/TEI//placeNameand your mappings to.(which will fetch “Boston Common”) and, if you need it,@id(which will fetch “BostonCommon”).
- If, for example, you’re simply grabbing content from a sequence of (parallel) XML nodes that are all located (in the TEI document) at
- You’re probably not going to get the mappings right the first time. If a field isn’t importing properly, the mapping is probably off in some way. A bit of trial and error will usually get you to something that works; try different ways of mapping to your desired tag / content, and you’ll eventually hit on something that works.
- Set as specific a mapping path as possible. We’ve found that if there’s any ambiguity in your mapping XPath (e.g., if you point to a tag has both an @attribute and content), the importer might not be able to fetch anything. XPath’s “@” and “dot” [.] selectors can be particularly useful in this regard.
- Lean on the online dev community. In the process of building the existing importers, we spent many hours on Stack Overflow, reddit, etc., reading threads that solve exactly the sort of issues we were facing. A simple online search for your problem will usually get you some answers.
Notes on the Tamper
If you need to use the Tamper submodule’s functionality (and you should, as it can be quite helpful), it’s important to note whether each tamper plugin is reusable between volumes or must be edited before importing future content.
A good example of a temper that must be reset or edited between imports is the Colorbox Annotation Importer’s tamper plugin for the “article-parent_link” (parent resource) field, which simply sets a default value (in this case, a node #) for all imported items. If you were to leave this tamper in place and attempt a new import on a fresh set of “notes-as-nodes,” which is the content type this importer imports to, the nodes imported will all be set as “belonging to” the wrong volume: i.e., the one previously imported.
For this reason, if you’re using an importer that is not one of RC’s 4 “vanilla” importers (Praxis/Editions XML/HTML), it’s a good idea to check the tamper settings before you execute an import. If you don’t, you might have a big mess to clean up.